One new tip that I got reading Deep Learning is clipping gradients. It's been common knowledge amongst practitioners for years but somehow I missed it.
 The steep regions resemble cliffs and they result from the multiplication of several large weights together. On the face of an extremely steep cliff structure, the gradient update step can move the parameters extremely far, usually jumping off the cliff structure together, undoing much of the work that had been done to reach the current solution.
The steep regions resemble cliffs and they result from the multiplication of several large weights together. On the face of an extremely steep cliff structure, the gradient update step can move the parameters extremely far, usually jumping off the cliff structure together, undoing much of the work that had been done to reach the current solution.
The gradient tells us the direction that corresponds to the steepest descent within an infinitesimal region surrounding the current parameters. Outside this tiny region, the cost function may begin to curve back upward. The update must be chosen to be small enough to avoid traversing too much upward curvature.
 One solution would be to have very small learning rate. This solution is problematic as it will slow training and maybe settle in a sub-optimal region. A much better solution is clipping the gradient (or norm-clipping). There are many instantiations of this idea but the main concept is to limit the gradient to a maximum number and if the gradient exceeds that number rescale the gradient parameters so the are limited within it. This customization retains the direction but limits the step size.
One solution would be to have very small learning rate. This solution is problematic as it will slow training and maybe settle in a sub-optimal region. A much better solution is clipping the gradient (or norm-clipping). There are many instantiations of this idea but the main concept is to limit the gradient to a maximum number and if the gradient exceeds that number rescale the gradient parameters so the are limited within it. This customization retains the direction but limits the step size.
For a high level understanding of deep learning click here
Problem
The problem with strongly nonlinear objective functions, such as those computed in recurrent or deep networks, is that their derivatives tend to be either very large or ver small in magnitude.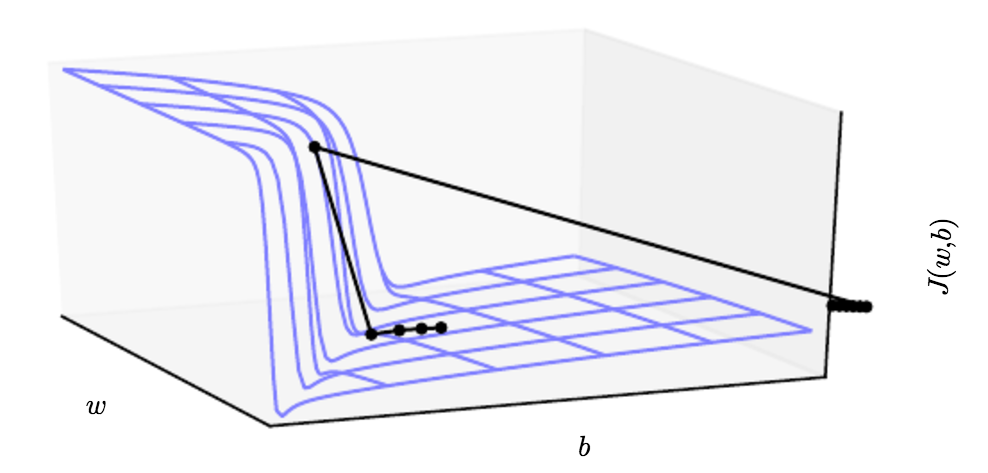
The gradient tells us the direction that corresponds to the steepest descent within an infinitesimal region surrounding the current parameters. Outside this tiny region, the cost function may begin to curve back upward. The update must be chosen to be small enough to avoid traversing too much upward curvature.
Solution
 One solution would be to have very small learning rate. This solution is problematic as it will slow training and maybe settle in a sub-optimal region. A much better solution is clipping the gradient (or norm-clipping). There are many instantiations of this idea but the main concept is to limit the gradient to a maximum number and if the gradient exceeds that number rescale the gradient parameters so the are limited within it. This customization retains the direction but limits the step size.
One solution would be to have very small learning rate. This solution is problematic as it will slow training and maybe settle in a sub-optimal region. A much better solution is clipping the gradient (or norm-clipping). There are many instantiations of this idea but the main concept is to limit the gradient to a maximum number and if the gradient exceeds that number rescale the gradient parameters so the are limited within it. This customization retains the direction but limits the step size. Thoughts
If your jobs involves training a lot of deep learning models automatically, then you should eliminate any unpredicable steps that require manual labor. We are engineers after all so whatever can be automated should be automated and no more. For me the problem was the unpredictability of the training. For a percentage of initializations in training mode gradient would explode. The reactionary solution was to lower the learning rate, but that costs time and money. In addition to that I wanted something that always works and thus can automated. Gradient clipping worked nicely in this regard and it allowed me to up the learning rate so that the training converges much faster.
Conclusion
Use gradient clipping everywhere, my default option is to limit to 1. In Caffe it is a single line in the solver and if your framework doesn't support it is easy to implement it yourself. You will save yourself enormous headaches and time.
* From the book "Deep Learning"Gradient Clipping in Tensorflow
1. Global Norm, this is the most usual case
optimizer = tf.train.AdamOptimizer(1e-3)
gradients, variables = zip(*optimizer.compute_gradients(loss))
gradients, _ = tf.clip_by_global_norm(gradients, 1.0)
optimize = optimizer.apply_gradients(zip(gradients, variables))
2. Local Norm
optimizer = tf.train.AdamOptimizer(1e-3)
gradients, variables = zip(*optimizer.compute_gradients(loss))
gradients = [
None if gradient is None else tf.clip_by_norm(gradient, 1.0)
for gradient in gradients]
optimize = optimizer.apply_gradients(zip(gradients, variables))
For a high level understanding of deep learning click here